
论文阅读|NAFNet
NAFNet 《Simple Baselines for Image Restoration》
代码:https://github.com/megvii-research/NAFNet
介绍了Image Restoration(IR)领域的块设计思想,值得借鉴。
但注意是22年的文章,SOTA的比较与现在相比可能不够权威了。
亮点
块设计中,可以不需要非线性激活函数。
思考流程清晰:从PlainNet -> baseline -> NAFNet,且每个模块添加的解释较为详细,适合查缺补漏。
涉及到了较为新颖的信息转化方式:对图像的通道信息的关注
Motivation
文章主要是基于HiNet,Restormer,Uformer,Local Vision Transformer,Swim Transformer,A convnet for the 2020s,MPRNet的理论和实验设置来展开。
[2105.06086] HINet: Half Instance Normalization Network for Image Restoration
[2111.09881] Restormer: Efficient Transformer for High-Resolution Image Restoration
Uformer: A General U-Shaped Transformer for Image Restoration
[2103.14030] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
此时IR领域的SORA解决方案,架构大多都是UNet的变体,性能提升同时带来复杂度升高。
系统复杂度:块间和块内,主要讨论块内复杂度。
块间复杂度
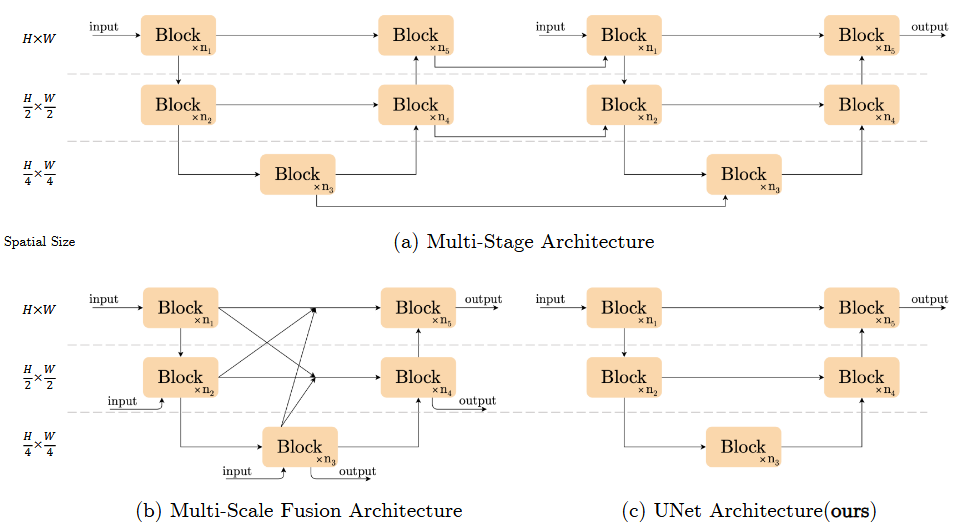
Multi-Stage: 基于将困难任务分解为多个子任务思想,后一阶段都是对前一阶段的优化。如
HiNet,MPRNetMulti-Scale Fusion: 单阶段UNet,但块间连接复杂,如
MIMO-UNet,DeepRFTSingle UNet: 单阶段UNet,如
Uformer,Restormer选择简单的结构,实验表明,效果仍然显著。
块内复杂度
块内设计,参考Restormer,Uformer,Swim Transformer
Restormer: Multi-Dconv Head Transposed Attention Module 和 Gated Dconv Feed-Forward Network上半部分是通道Attention,下半部分是gated linear units(GLU),两层的逐元素相乘,其中一层是非线性激活函数
Uformer: window-based multi-head self-attention 基于窗口的多头注意力,dConv局部信息捕捉注意力机制计算耗时,但有全局信息 -> 基于固定窗口大小的注意力 -> 通道注意力能感知到全局信息,且计算消耗相对较少。
再加以深度卷积
dConv辅助,捕捉局部信息。
概览
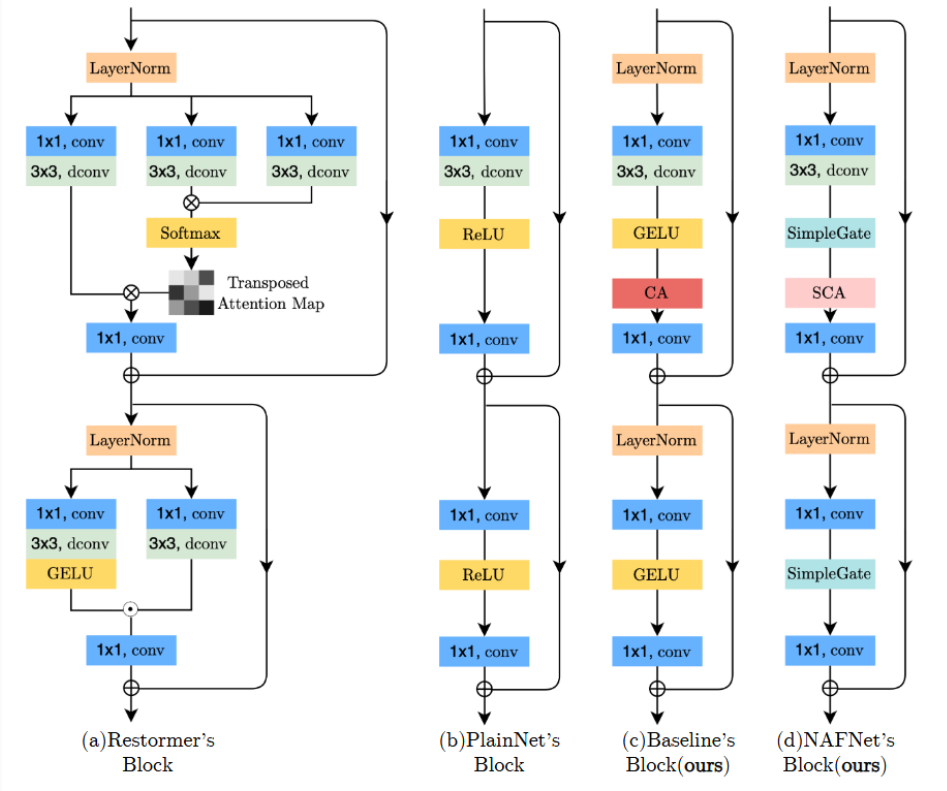
PlainNet
Conv,ReLU,shortcut,
组织方式:仿照Swim Transformer,local Vision transformer
Why not transformer? 不是SOTA方法关键,且dConv照样能捕捉局部信息,可平替。
Baseline
LN,Conv,GELU,CA,shortcut
Normalization
Batch Normalization: 小批次可能带来不稳定统计特性
Instance Normalization:
Hinet引入IN避免小批次问题,但性能不一定提升,且需要人工微调
Layer Normalization:
transformer时代下,Restormer,Uformer,Swin Transformer等主流方法都采用,实验表明,在学习率变大时,加入LN可使训练平滑。
Activation
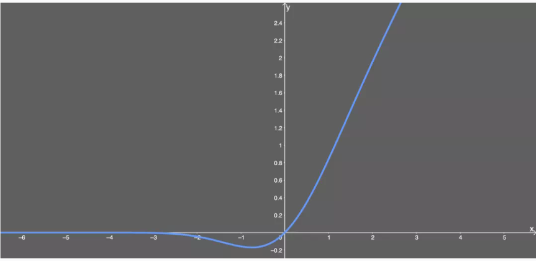
ReLU: max(0,x),在SOTA方法中,有用GELU代替ReLU的趋势
GeLU:
Attention
vanilla attention:对所有特征线性加权,得到目标特征,保证了每个特征带有全局信息,但显然带来计算资源过大的问题。
固定窗口Attention:
SwimIR,SwinTransformer,Uformer采用,本文认为不如直接用dConv捕捉局部信息。
channel-wise attention:
Restormer将空间注意力改为通道注意力,保留全局信息又减少计算代价(有相关论文证实CA的信息能力)
Chu, X., Chen, L., , Chen, C., Lu, X.: Improving image restoration by revisiting global information aggregation. arXiv preprint arXiv:2112.04491 (2021)
Waqas Zamir, S., Arora, A., Khan, S., Hayat, M., Shahbaz Khan, F., Yang, M.H., Shao, L.: Multi-stage progressive image restoration. arXiv e-prints pp. arXiv–2102 (2021)
NAFNet
LN, Conv, SimpleGate,SCA,shortcut
灵感来源:SOTA方法共性,都采用了GLU,对GLU改造,衍生出了SimpleGate和SCA
细节
GLU
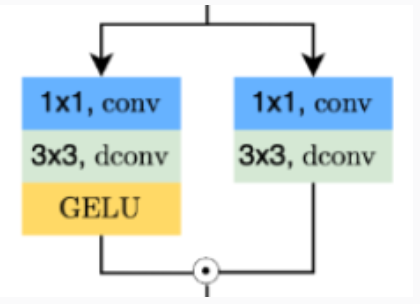
SimpleGate
对比GELU:
于是反过来思考,GLU是激活函数的泛化体。
再看其式子,哪怕是
提出SimpleGate:
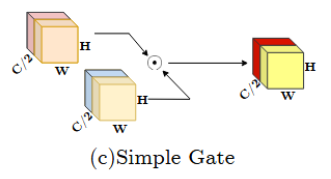
SimpleGate。
至此,SImpleGate替换掉GELU。
SCA
正常的Channel Attention(CA):
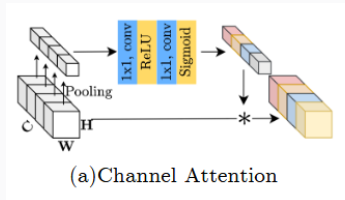
CA将空间的信息压缩至通道(做全局平均池化,HW改变,C不变),然后通过多层感知机计算注意力分数,每个通道赋权值,最后加权至原图。
简化的Simplified Channel Attention(SCA):
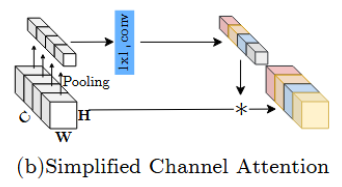
总结
信息的转换方式简单有效:将空间信息转换到通道信息,且仅采用一层conv。
这种方式能有效,感觉得SimpleGate和SCA连着一起用,SimpleGate使自身信息产生交互,使得数据有一定自我认知,然后SCA再将关键信息抓出来,再赋予到原块中,使得关注该信息。(SCA不用对这个信息再多做多层感知机那样的处理,相当于SimpleGate做了这一部分。)