
前沿研究|FLUX
FLUX.1
官方简介:Announcing Black Forest Labs - Black Forest Labs
官方代码:https://github.com/black-forest-labs/flux
Diffusers运行FLUX.1:https://huggingface.co/docs/diffusers/main/en/api/pipelines/flux
权重:black-forest-labs (Black Forest Labs)
技术报告:未上线
作者背景
Black Forest Labs开发,成员基本是
Stable Diffusion 3的作者。
代表作:
VQGAN: [2012.09841] Taming Transformers for High-Resolution Image Synthesis
Latent Diffusion: [2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models
SDXL:[2307.01952] SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Stable Video Diffusion:[2311.15127] Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable Diffusion 3(架构和前面的都不一样):[2403.03206] Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Stable Diffusion系列:维基百科快速了解Stable Diffusion
- Wikipedia
内容简介
FLUX.1 [pro]: FLUX.1 系列的最强模型,只能通过付费的 API 或者在线平台使用。
FLUX.1 [dev]:FLUX.1 [pro] 的指引蒸馏(guidance-distilled)模型,质量与文本匹配度与原模型相近,运行时更高效。
FLUX.1 [schnell]:为本地开发和个人使用而裁剪过的本系列最快模型。据 Diffusers 中的文档介绍,这是一个 Timestep-distilled(时间戳蒸馏)的模型,因此仅需 1~4 步就可以完成生成。无法设置指引强度。
FLUX.1 [dev] 用到的指引蒸馏技术似乎来自论文On Distillation of Guided Diffusion Models,其目标是让模型直接学习 Classifier-Free Guidance (CFG) 的生成结果,使得模型一次输出之前要运行两次才能得到的指引生成结果,节约一半的运行时间。
FLUX.1 的生成神经网络基于 Stable Diffusion 3 的 MMDiT 架构和并行的 DiT 块,参数量扩大至 120 亿。生成模型是根据流匹配(flow matching)推导的扩散模型。此外,为了提升性能与效率,模型新引入了旋转式位置编码 (RoPE) 和并行注意力层。
FLUX.1 在 Stable Diffusion 3 的基础上,加了 RoPE 和并行注意力层。
拼图之路
想要研究FLUX,得先弄明白Stable Diffusion 3
Stable Diffusion 3
《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》
整流生成模型(Rectified Flow),Transformer网络(DiT),模型参数扩增,实现高质量文生图。
Motivation
对于图像生成,希望让模型学习数据的分布,但很难表示出一个适合采样的复杂分布。
我们会把学习一个分布的问题转换成学习一个简单好采样的分布到复杂分布的映射。一般这个简单分布都是标准正态分布。
此时问题便转化为学习映射。
近年来包括扩散模型在内的几类生成模型用一种巧妙的方法来学习这种映射:从纯噪声(标准正态分布里的数据)到真实数据的映射很难表示,但从真实数据到纯噪声的逆映射很容易表示。
先人工定义从图像数据集data到噪声noise的变换路线,再让模型学习逆路线。让噪声数据沿着逆路线走,就实现了图像生成。
文章认为,虽然指定从data到noise的正向路径,但是具体选择哪一条路径,对采样过程会产生重要影响。
【例如,去噪时如果没有将data中的noise去除干净,会产生训练和测试分布的差异性,造成artifact现象。】
所以前向加噪的路径选择是十分重要的,因为它会影响反向去噪时的学习,从而影响采样效率。
弯曲的路径,需要许多积分过程模拟,直线路径可以一步模拟,而且误差累积少。 -> 直接影响采样效率
Rectified Flow
理论基础好,但是还没有决定性的实践验证。本文打算基于此进行验证。
创新点
- 为整流模型引入新的噪声采样器
- 设计了一种新颖的、可扩展的文本到图像合成架构,允许在网络内的文本和图像令牌流之间进行双向混合。
- 对模型进行了扩展研究,并证明它遵循可预测的扩展趋势
整流模型
流匹配相关文章:
《Flow matching for generative modeling》2023
《Flow straight and fast: Learning to generate and transfer data with rectified flow》2022
《Building normalizing flows with stochastic interpolants》2022
理论部分。
Flow Matching
从来自噪声发布
直接用求解器求解这个式子,计算代价很昂贵。
于是更加有效的方法:都是通过一个向量场
向量场u_t的构造
原目标的条件化
定义一个前向路径
,介于 和 之间 这个式子描述的是从噪声中产生实际分布 ,概率路径 的表达形式。其中, , 根据ODE的式子(条件流与场的关系),条件流与场:
此处是:
能进行边缘化,产生
于是,目标函数简化为条件形式,
此处,写作:
[!NOTE]
来自《flow matching》原文:假定
已知是一个高斯概率路径 ,根据 的仿射变换 ,以及条件流与场的关系,于是就能给出定义 的向量场: 其中, 令
,则 等价于 . 通用变量替换:令
,于是有 结果,
能产生高斯路径 ,从而知道 的形式。
此处产生
通用表示:改造为噪声预测
令信噪比(signal-to-noise)
重写
据此,可写出各种加权形式的损失函数,不同损失函数可能会影响优化轨迹,为对不同方法进行统一分析,根据《Understanding diffusion objectives as the elbo with simple data augmentation.》
可写为:
Flow Trajectories
流动轨迹,此处考虑不同变体。
Rectified Flow
《Flow straight and fast: Learning to generate and transfer data with rectified flow》
《Building normalizing flows with stochastic interpolants》
《Flow matching for generative modeling》
Rectified Flows (RFs):
将前向路径定义为从数据分布到标准正态分布的直线路径。
EDM
《Elucidating the design space of diffusion-based generative models》
《Understanding diffusion objectives as the elbo with simple data augmentation.》2023

Cosine
《Improved denoising diffusion probabilistic models 》2021
《Understanding diffusion objectives as the elbo with simple data augmentation.》2023
其中,
结合v-prediction,
(LDM-)Linear
《High-resolution image synthesis with latent diffusion models》
LDM采用的是改良版DDPM策略,都是保留方差(VP)策略。

SNR Samplers
为RF模型专门定制的采样器。
原先RF存在的问题:
RF损失函数在
[!NOTE]
时,最佳预测是 的均值
时,最佳预测是 的均值
因此,我们希望通过更频繁地采样中间时间步长,为这些时间步长赋予更高的权重。接下来,我们描述用于训练模型的时间步长密度。
将时间步长t的均匀分布
Logit-Normal Sampling
Mode Sampling with Heavy Tails
Logit-Normal方法在0和1处的密度会消失,于是对此改进。
在RF工作中,就已广泛使用该方法。
CosMap
《Improved denoising diffusion probabilistic models, 2021》
在RF设置中,采用了cosine策略。
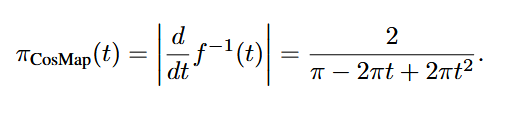
文生图框架
同时考虑两种模态,图像与文字。
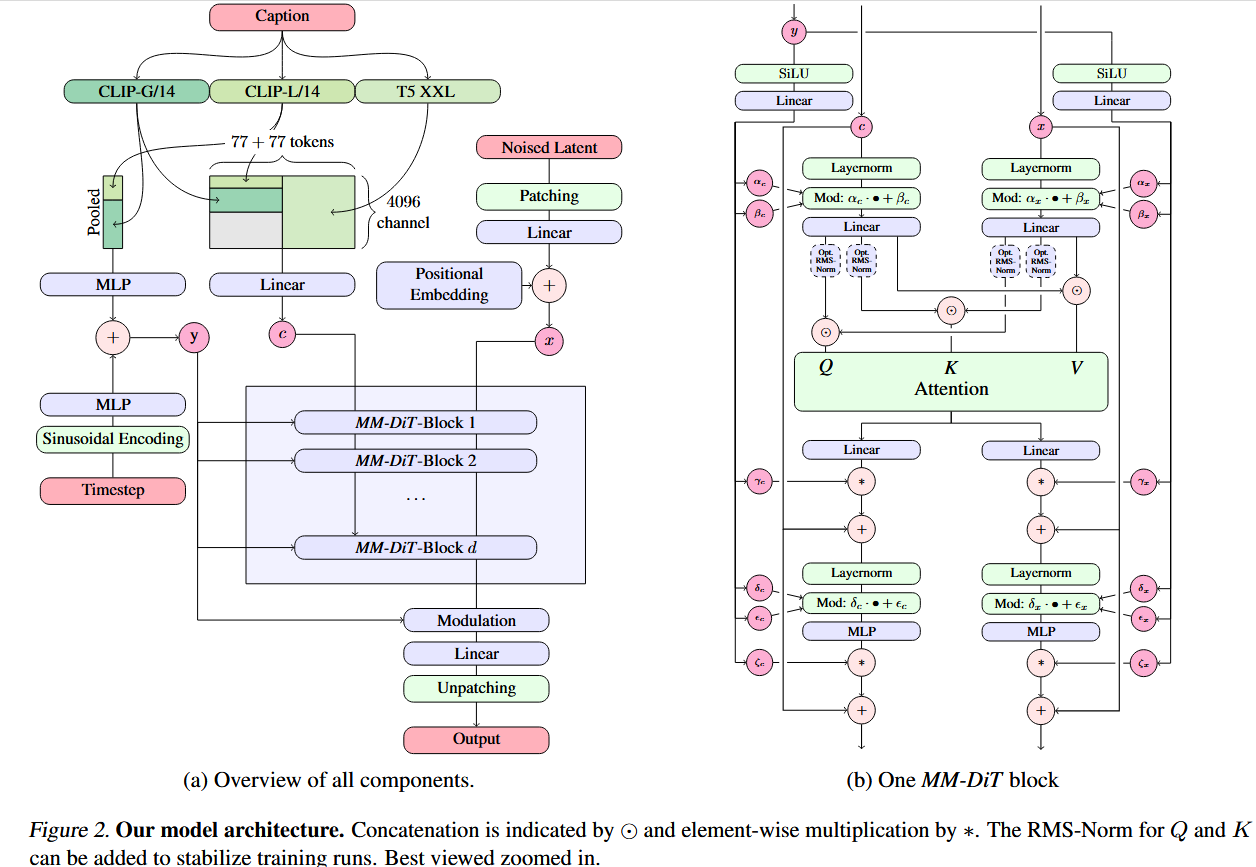
基础设置
autoencoder: LDM的预训练autoencoder,在latent
space。
Image and Text Representation: 细节见附录B.2
Backbone
Multimodal Diffusion Backbone 多模态扩散主干
架构基于DiT,但DiT只考虑了类别条件的图像生成,使用一个模态调节机制(modulation mechanism),在网络中条件化时间步和类别标签。
类似地,我们将时间步t的embedding和modulation mechanism的输入。
然而,由于池化后的文本表示仅保留了关于文本输入的粗粒度信息(Podell
等,2023),因此网络还需要来自序列表示
DiT:《Scalable diffusion models with transformers》2023
Podell 等,2023: 《Improving latent diffusion models for high-resolution image synthesis》
Encode
因此,我们构造了一个序列sequence,由text和image的embedding共同组成。
具体来说,我们添加位置编码,并将潜在像素表示
在把text和image,encoding为共同模态后,连接concat两个sequence。
然后,followDiT,使用一个modulated attention和MLPs
具体来说,就是MM-DiT Block完成encode操作:
由于文本和图像的嵌入在概念上有很大不同,我们为这两种模态使用了两组独立的权重。如图 2b 所示,这相当于为每种模态使用两个独立的Transformer,但在注意力操作中将两种模态的序列连接起来,以便两种表示可以在各自的空间中工作,同时考虑到对方。