
论文阅读-Attention
《Attention Is All You Need》
https://github.com/ tensorflow/tensor2tensor
我们提出了一种新的简单网络架构,即 Transformer,它完全基于注意力机制,完全省去了递归和卷积。
Introduction
RNN,LSTM,gated recurrent neural networks(GRU)等
递归模型本质,生成一个个
在这项工作中,我们提出了 Transformer,一种摒弃递归并完全依赖注意力机制来建立输入和输出之间全局依赖关系的模型架构。Transformer允许显著更多的并行化。
Background
随着距离增加会难以学习依赖关系,而Transformer采用Multi-Head Attention抵消。
Self-Attention(intra-attention):
单一sequence中计算不同位置的特征表示。
Model Architecture
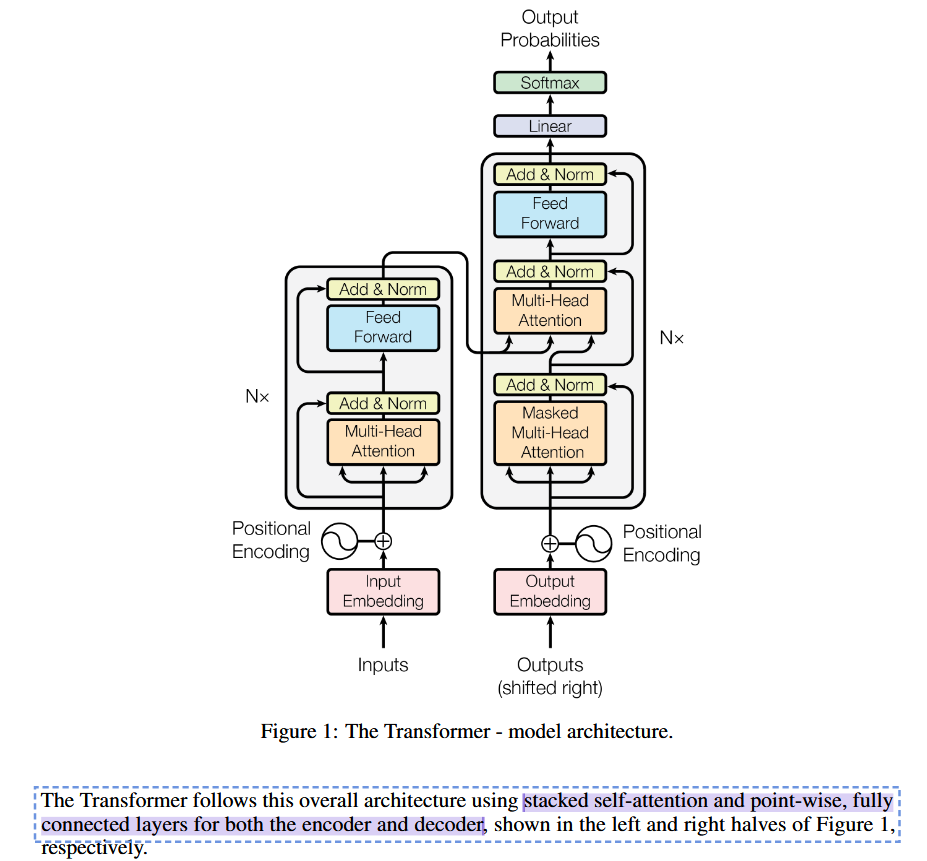
encoder将输入decoder给定
每一次的过程是auto-regressive:
[!NOTE]
At each step the model is auto-regressive , consuming the previously generated symbols as additional input when generating the next.
在生成下一步时,会将前面的符号作为额外输入。
Encoder and Decoder Stack
Encoder
编码器由 N=6 个相同的层堆叠而成。每一层包含两个子层。
- 第一个是多头自注意力机制
Multi-Head Attention - 第二个是一个简单的逐位置全连接前馈网络(positionwise fully connected
feed-forwardnetwork)。
每个子层都使用了残差连接,然后进行Layer Normalization,即每个子层的输出是
为了方便残差连接,模型中的所有子层以及嵌入层都生成维度为
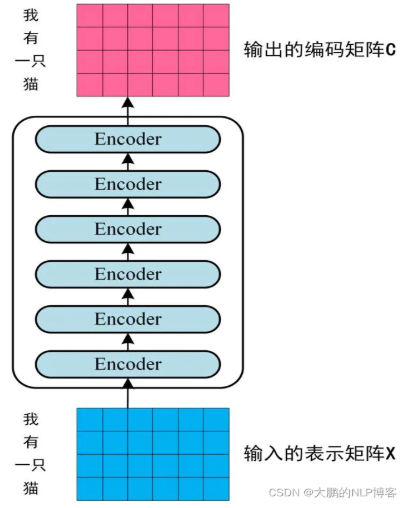
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
Decoder
解码器由 N=6 个相同的层堆叠而成。 每一层包含三个子层。
- 第一个是
Masked Multi-Head Attention,我们对Deocder中的自注意力子层进行了修改,以防止当前位置关注到后续位置。
这种掩码(masking),结合输出嵌入向量偏移一个位置的事实,确保位置 i 的预测只能依赖于位置 i 之前已知的输出。
通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
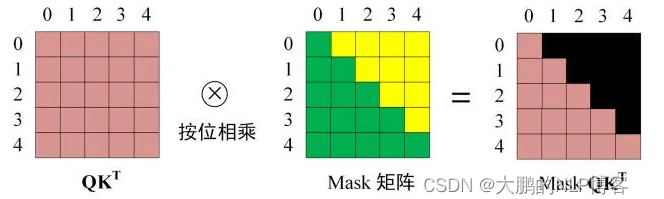
黄色是遮挡,即值是0。然后在
- 第二个是相比
Encoder多增加的多头自注意力机制Multi-Head Attention,该子层对编码器堆叠的输出执行多头注意力机制。
K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。(如果是第一个Decoder block则用输入矩阵X计算)
- 第三个是一个简单的逐位置全连接前馈网络(positionwise fully connected
feed-forwardnetwork)。
每个子层都使用了残差连接,然后进行Layer Normalization
Attention
mapping a query and a set of key-value pairs to an output将查询和一组键值对映射到输出
其中,输出值是value的加权和,权重是query和key产生。
Scaled Dot-Product Attention
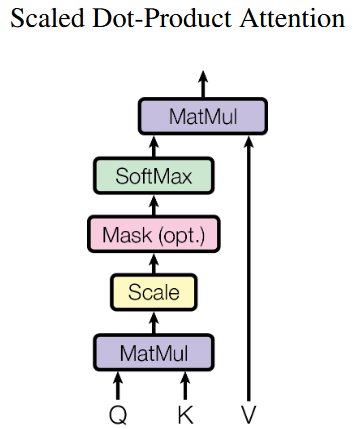
querys,keys: dimension
values: dimension
Q,K,V是由嵌入向量X乘以三个不同的权值矩阵
整个过程可以分成7步:
- 将输入单词转化成嵌入向量;
- 根据嵌入向量得到 q,k,v三个向量;
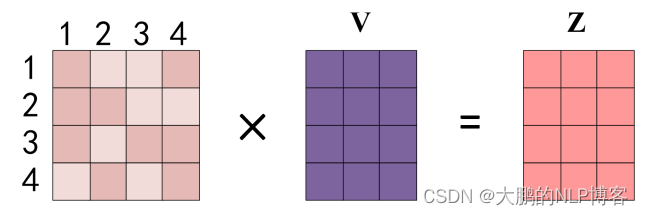
- 为每个向量计算一个score:
; - 为了梯度的稳定,Transformer使用了score归一化,即除以
- 对score施以softmax激活函数;
- softmax点乘Value值
,得到加权的每个输入向量的评分 ; - 相加之后得到最终的输出结果 z:
。

具体的例子含义:
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention
系数,最终单词
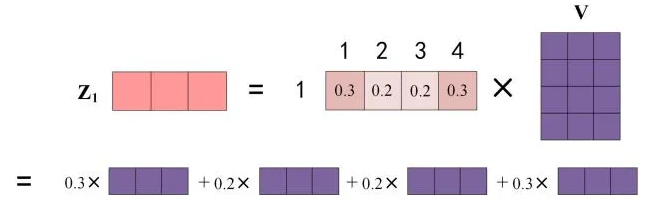
Dot-Product Attention :
additive Attention: using a feed-forward network with a
single hidden layer
二者,更倾向于使用Dot-Product Attention,因为它能以矩阵形式表示,实践中计算速度快,效率高。
[!NOTE]
why scale?
当
的值较小时,这两种机制的表现相似; 然而,随着
增大,添加式注意力(additive attention)在没有缩放的情况下优于点积注意力(dot product attention)。 我们推测,当
较大时,点积的值会变得很大,这会使得 softmax 函数进入梯度非常小的区域。为了抵消这种效应,我们将点积结果缩放为 。
Multi-Head Attention
在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,而可能忽略了其它位置。因此作者采取的一种解决方案就是采用多头注意力机制(MultiHeadAttention)。
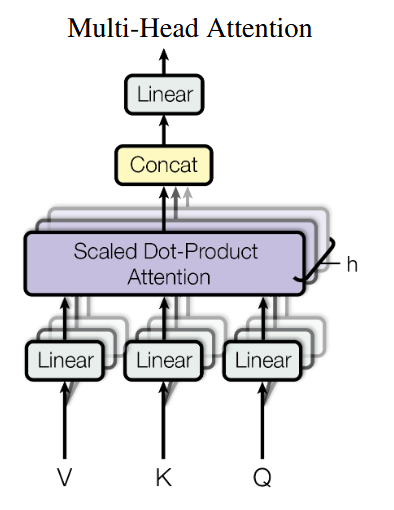
对Q,K,V进行多次线性变换Linear,然后作注意力计算Attention,最后进行concat拼接,投影一次Linear,得到最终结果。
多头注意力允许模型共同关注来自不同位置的不同表示子空间的信息,而单次注意力则会平均不同位置的信息。
[!NOTE]
set:
, 每个头的维度减少,计算成本与具有全维度(
)的单头注意力相似。
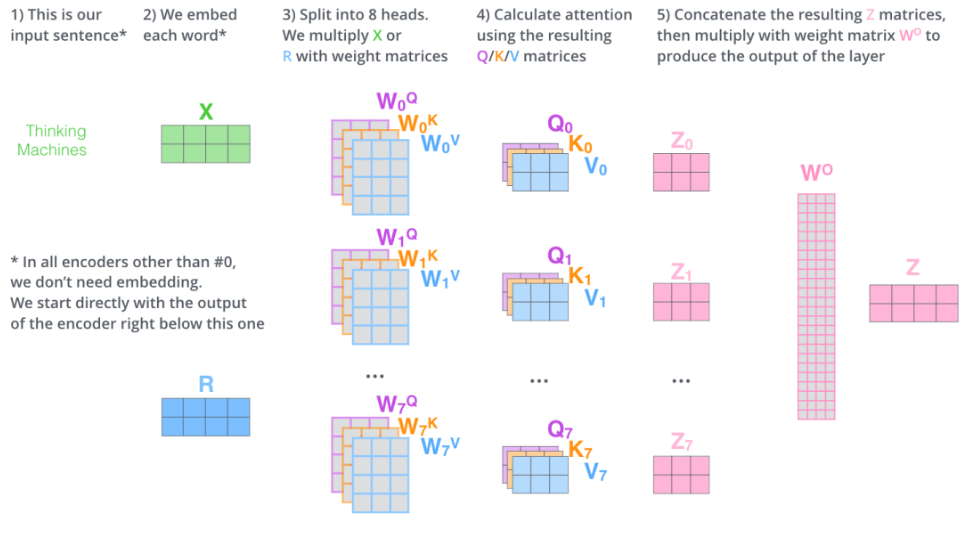
最后要拼接concat每个头,然后还要再传入一个Linear层,得到最终输出Z。
输出的矩阵Z与其输入的矩阵X的维度是一样的
Attention in our Model
Transformer使用Multi-head Attention:
encoder-decoder attention: 查询(query)来自前一个decoder层,键(key)和值(value)来自encoder的输出。
效果:能使得decoder中的每个位置能关注input sequence的所有位置。
理解:query携带有前一个词与前面所有词的关系信息,当前key和value则是携带当前词的信息,作注意力计算,则将当前词与前面所有部分关联。
encoder:当前层encoder内部的
self-attention,q,k,v都来自同一个地方(前一层的encoder)效果:能使得encoder的每个位置能关注前一层encoder的所有位置。
decoder:类似encoder,但是为了保持自回归特性,我们需要防止左侧信息流动。在缩放点积注意力(scaled dot-product attention)中实现这一点,方法是将softmax输入中的所有非法连接对应的值设为负无穷(−∞),从而遮蔽掉不合法的连接。
[!NOTE]
在自注意力机制(Self-Attention)中,模型可以在处理当前位置时,访问序列中所有其他位置的信息。
然而,在解码器(Decoder)中,尤其是在自回归生成任务(如文本生成)中,为了确保每个时间步的生成只依赖于已经生成的部分,不能“偷看”未来的输出。
故使用了
masking操作,具体地,模型在进行点积注意力计算时,通过对softmax输入进行掩蔽,将所有非法的连接(即当前时刻不能访问未来时刻的信息)设置为负无穷(−∞)。这样,在softmax计算时,这些被掩蔽的连接会导致权重接近零,从而有效地阻止了信息流向未来的时间步,
Position-wise Feed-Forward Networks
前馈网络,由两个linear变换以及中间一个ReLU激活函数组成。
Embeddings and Softmax
Embeddings:使用learned
embeddings,将输入和输出token,转化为维度是
在解码器decoder的输出之后,我们使用一个线性变换和softmax函数将模型的输出转换为下一个标记的概率分布。
在我们的模型中,我们在两个嵌入层和pre-softmax的线性变换之间共享相同的权重矩阵
在嵌入层中,我们将权重矩阵乘以
Positional Encoding(PE)
由于模型中是没有递归(recurrence),也没有卷积(convolution)。为充分利用sequence的顺序,需要引入token的位置信息。
positional encodings添加到input embeddings,
此处采用不同频率下的添加。
也就是说,位置编码的每个维度都对应一条正弦曲线。
[!NOTE]
选择这个函数的原因:能让模型更容易地学习通过相对位置进行注意力机制,因为对于任何固定的偏移 k,
可以表示为 的线性函数。 尝试过
learned positional embedding,效果一致。其中,pos 表示单词在句子中的位置,d 表示PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。使用这种公式计算 PE 有以下的好处:
使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。
因为
。 将单词的词 Embedding 和位置 Embedding 相加,就可以得到单词的表示向量 x,x 就是 Transformer 的输入。
我们选择了正弦波版本,因为它可能使模型能够在训练期间未遇到的更长序列长度上进行推断。
Why Self-Attention
与卷积层,递归层进行比较,他们往往是将一个变长序列映射至一个等长序列,如隐藏层。
考虑三个目标:
每层的计算复杂度
可以并行化的计算量
网络中长程依赖关系的路径长度
影响学习这种依赖关系能力的一个关键因素是信号在网络中前向和反向传递所需的路径长度。输入和输出序列中任意位置组合之间的路径越短,学习长程依赖关系就越容易

[!NOTE]
自注意力层通过恒定数量的顺序操作连接所有位置,而递归层则需要 O(n) 顺序操作。在计算复杂度方面,当序列长度 n 小于表示维度 d 时,自注意力层比递归层更快。
为了提高处理非常长序列的计算性能,可以将自注意力限制为仅考虑输入序列中以相应输出位置为中心的大小为 r 的邻域。这将使最大路径长度增加到 O(n/r)。
卷积是昂贵的,但可分离卷积能减少计算量,而其计算量与我们的self-attention层+feed-forward层是一样的。
除此之外,自注意力可能是更具备解释性的。(附录中讨论),
每个单独的注意力头显然学习了执行不同任务的能力,许多注意力头似乎表现出与句子的句法和语义结构相关的行为。
Training
每个子层在输出时使用了dropout
补充
cross attention
Cross-Attention是两端的注意力机制,然后合起来,输入不同。
Cross-attention将两个相同维度的嵌入序列不对称地组合在一起,而其中一个序列用作查询Q输入,而另一个序列用作键K和值V输入。
[!NOTE]
- Transformer架构中混合两种不同嵌入序列的注意力机制
- 两个序列必须具有相同的维度
- 两个序列可以是不同的模式形态(如:文本、声音、图像)
- 一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V
区别self-attention:
Cross-attention的输入来自不同的序列,Self-attention的输入来自同序列,也就是所谓的输入不同,但是除此之外,基本一致。
- 拥有两个序列S1、S2
- 计算S1的K、V
- 计算S2的Q
- 根据K和Q,计算注意力矩阵
- 将V应用于注意力矩阵
- 输出的序列长度与S2一致
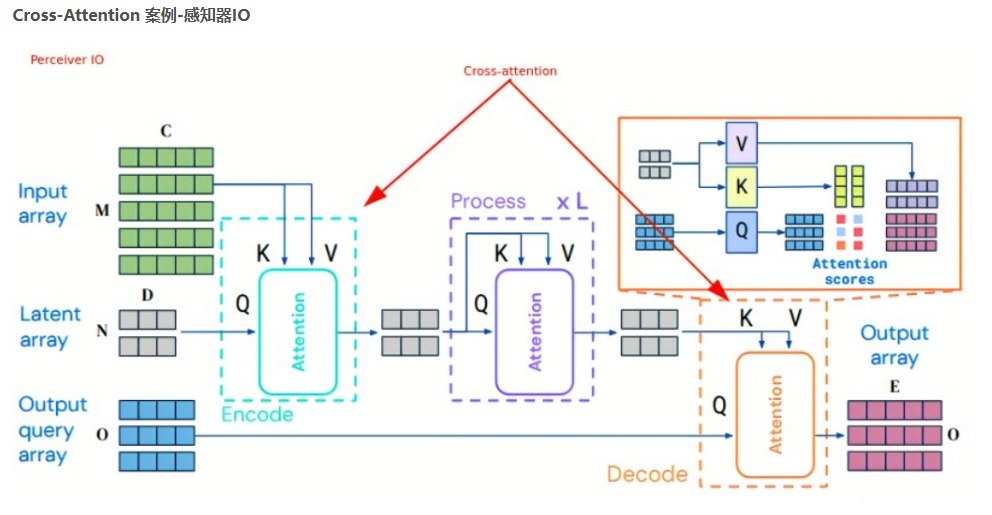
感知器IO是一个通用的跨域架构,可以处理各种输入和输出,广泛使用交叉注意:
- 将非常长的输入序列(如图像、音频)合并到低维潜在嵌入序列中
- 合并“输出查询”或“命令”来解码输出值,例如我们可以让模型询问一个掩码词
参考
Self -Attention、Multi-Head Attention、Cross-Attention_cross attention-CSDN博客
《attention is all you need》