
论文阅读-DiT
《Scalable Diffusion Models with Transformers》
[!NOTE]
Transformer 在许多领域都有很不错的表现,尤其是近期大语言模型的成功证明了scaling law 在 NLP 领域的效果。Diffusion Transformer(DiT)把 transformer 架构引入了扩散模型中,并且试图用同样的 scaling 方法提升扩散模型的效果。DiT 提出后就受到了很多后续工作的 follow,例如比较有名的视频生成方法 sora 就采取了 DiT 作为扩散模型的架构。
DiT 使用的是
latent diffusion,VAE 采用和Stable Diffusion相同的KL-f8,并且使用了Improved DDPM,同时预测噪声的均值和方差。
backbone不再是普遍的UNet,而是换成了transformer。scalability的分析:Gflops测量前向通道的复杂度。
Transformer的深度/宽度或输入token增加,都会导致较高的Gflops伴随较低的FID
[!NOTE]
class-conditional ImageNet生成图像时,依赖输入的类别标签信息来生成对应图像。
指在 ImageNet 数据集上训练或使用的条件生成模型,类别标签作为条件,用于指导生成模型输出特定类别的图像。
Introduction
transformer在自回归模型中应用广泛,但是在生成建模框架中很少见。
在生成建模框架中,扩散模型是图像生成的前沿研究.
Prafulla Dhariwal and Alexander Nichol. 《Diffusion models beat gans on image synthesis》. In NeurIPS, 2021.
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 《Hierarchical text-conditional image generation with clip latents》. arXiv:2204.06125, 2022
都选择的是U-Net架构作为backbone
[!NOTE]
扩散模型中的
U-Net架构DDPM第一次对扩散模型引入UNet,且U-Net在像素级自回归模型和conditional GANs取得成功,后来继承PixelCNN++又进行修改。
改进后的
U-Net:卷积部分由ResNet块组成,额外的空间自注意力块(区别于标准UNet)。《Diffusion models beat gans on image synthesis》也对UNet的架构选择进行消融实验,如自适应归一化层为卷积层注入条件信息等。
但总体的高级设计仍是UNet
在本文中,主要弄清楚架构选择在扩散模型中的重要性。
我们发现,UNet对于扩散模型的表现性能不是关键,可以被Transformers替代。于是,关于transformer的很多研究,也许能继承过来使用,如可扩展性,稳健性,效率等。
DiT,基于ViT的基础上,与传统卷积结构相比在图像识别领域,展现出了更好的扩展性 , [主要就是利用了patchify吧]
ViT: 《An image is worth 16x16 words: Transformers for image recognition at scale》
LDM:《High-Resolution Image Synthesiswith Latent Diffusion Models》
DiT,基于LDM的框架,VAE‘s latent space,可以将U-Net backbone用transformer替代。
Related Works
Transformers
increasing model size, training compute
《Scaling laws for neural language models. arXiv:2001.08361, 2020》
生成CLIP image embeddings: 《Hierarchical text-conditional image generation with clip latents》
先前的研究,都是拿transformer来自回归预测像素,直到DDPM的出现,开始针对DDPM结合transformer,如生成CLIP image embeddings。
In this paper, we study the scaling properties of transformers when used as the backbone of diffusion models of images.
DDPMs
Diffusion理论,Score-based Models
《Estimation of nonnormalized statistical models by score matching》
《Generative modeling by estimating gradients of the data distribution》
成功案例
Glide: Towards photorealistic image generation and editing with text-guided diffusion models.
Hierarchical text-conditional image generation with clip latents.
High-resolution image synthesis with latent diffusion models
Photorealistic text-toimage diffusion models with deep language understanding.
GAN:
Generative adversarial nets
DDPM的各种改进:
采样技术
DDPM:《Denoising diffusion probabilistic models》
EDM:《Elucidating the design space of diffusion-based generative models.》
DDIM:《Denoising diffusion implicit models》
技巧:classifier guidance
《Classifier-free diffusion guidance》
DDPM
级联DDPM,并行训练采样器和低分辨率基础扩散模型。
《Diffusion models beat gans on image synthesis.》
《Cascaded diffusion models for high fidelity image generation.》
以上全部都是UNet架构
还有一篇研究是基于DDPM的注意力架构
《Scalable adaptive computation for iterative generation.》
“Concurrent work [24] introduced a novel, efficient architecture based on attention for DDPMs;
we explore pure transformers.“
而本文研究的,是pure transformers
Architecture complexity
评估指标:(parameter counts)参数量,可能不是图像模型复杂性的代表手段(因为没有考虑图像分辨率等)
本文采用的是Gflops
相关工作,但他们分析的是UNet的扩展性和Gflop属性。
《Improved denoising diffusion probabilistic models.》
《Diffusion models beat gans on image synthesis》 本文要分析的是transformer的扩展性和Gflop属性
Diffusion Transformers
Preliminaries
(1)扩散理论(DDPM)
前向加噪:
扩散模型训练的过程是在学习反向去噪。
[!NOTE]
逆向过程模型,使用
的变分下界的对数似然(《Auto-encoding variational bayes》)进行训练,可简化为: 其中, 和 都是高斯分布,故可用两个分布的均值和协方差来评估 。 而
可被重参数化为与噪声预测网络 相关,于是模型的训练目标可以被写作预测噪声 和实际噪声 的均方误差。 而为了让协方差 也能用来训练模型,需对 进行优化。 遵循《Improved denoising diffusion probabilistic models.》
- train
with , and train with the full .
当
(2)Classifier-free guidance
条件扩散模型,需要引入一个额外信息作为输入,通常是一个类标签
此时,要学习的目标变为:
根据《Classifier-free diffusion
guidance》,可采用该技术来帮助采样过程,得到使得
又根据贝叶斯:
(3)Latent diffusion models
直接在高分辨率像素空间训练是计算代价高的,《High-resolution image synthesis with latent diffusion models.》解决了这个问题。
其采用two-stage方法:
训练一个autoencoder,encoder(
)将图像 压缩到一个更小的空间特征 ,decoder(D)负责将扩散模型得到的结果 还原为 训练一个扩散模型,接收的是
,而不是 新的图像从
采样,再通过decoder(D),将其解码为图像
[!IMPORTANT]
在本文中,我们将 DiT 应用于潜在空间,尽管它们也可以在不修改的情况下应用于像素空间。
这使得我们的图像生成管道成为一种基于混合的方法;
我们使用现成的卷积 VAE 和基于 transformer 的 DDPM。
Diffusion Transformer Design Space
DiT,目标是尽可能忠实于标准transformer架构,以保留其scaling特性。
DiT主要是基于ViT基础(图像的patches序列)和训练DDPM下的图像(特别是空间特征)
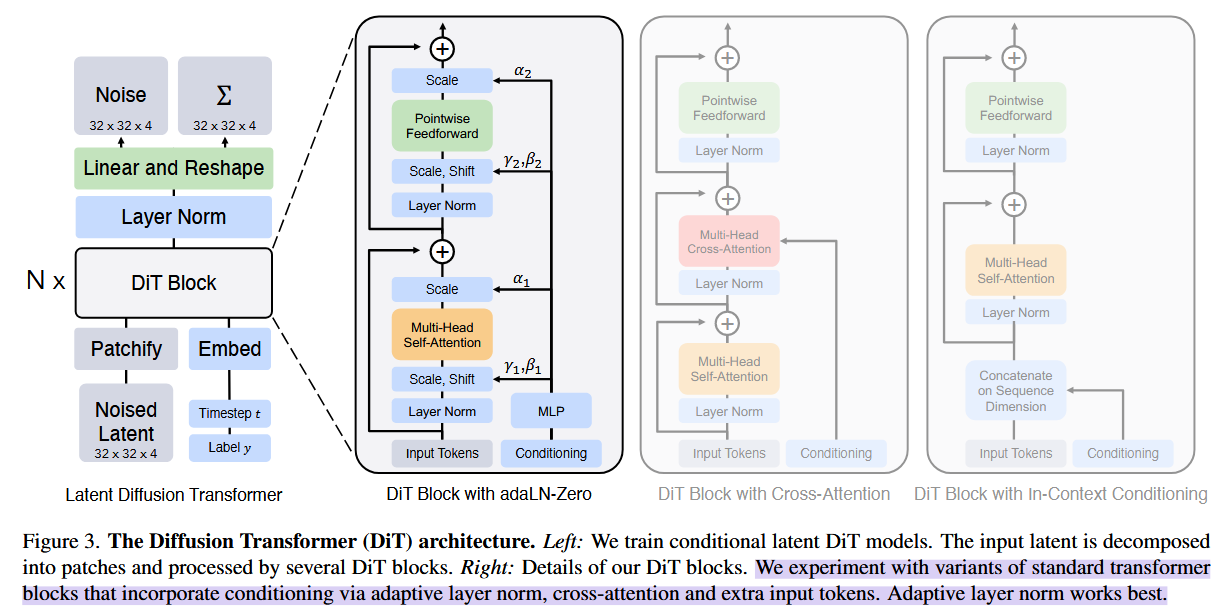
Patchify
DiT的输入是空间特征patchify,将
然后,为所有input tokens添加positional embeddings(the
sine-cosine version)。 (follow standard ViT)
[!NOTE]
的数量由patch size超参数 决定 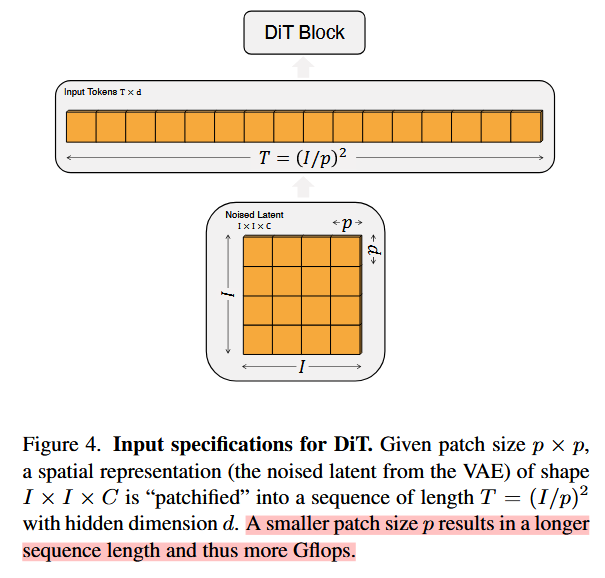
patch是在
的基础上进行,经过转换后得到的token序列长度为 。
越小,导致序列长度越长,导致参数量大(Gflops增加)。 tips:虽然对Gflops会增加,但是改变
不影响下游的参数量。 (本文设置了 )
DiT block design
除了噪声图像输入,扩散模型还需要处理其他条件信息,如噪声时间步长
探索了四种transformer变体,它们以不同方式处理条件的输入。
原版ViT:
变体:
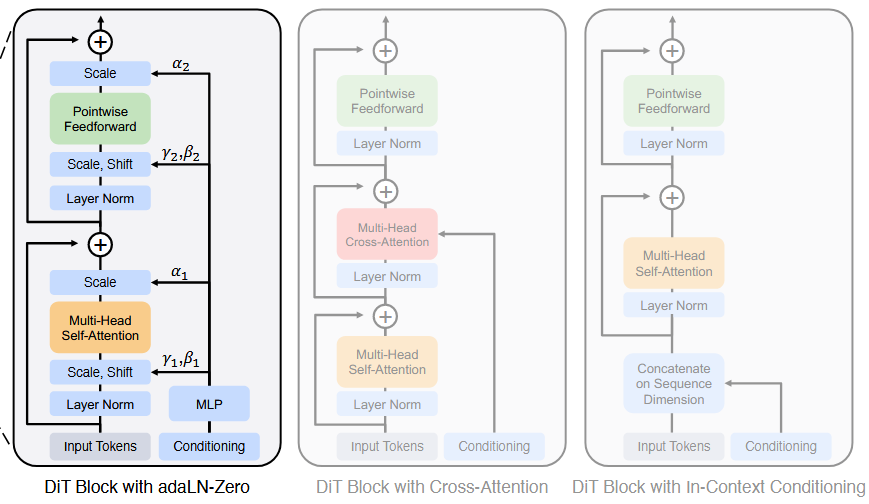
[!NOTE]
In-context conditioning只是在输入部分做了改动,将
和 的向量嵌入作为额外token附加到输入token。 做法是类似ViT中的cls。 在最后一个块后,从序列中删除了条件tokens。
无需修改ViT块。
此方法中,引入的Gflops可忽略不计
Cross-attention block在输入部分不同了,将
和 的向量嵌入合并,但是和图像token分离开。 注意力部分,在多头自注意力后,还增加了多头交叉注意力。
【类似《attention is all you need》的decoder结构,也类似LDM的class labels的处理】
此方法中,引入了最多的Gflops,大约有15%开销。
[!NOTE]
Adaptive layer norm (adaLN) blockadaptive normalization layers在GANs的广泛使用:
adaLN:《Film: Visual reasoning with a general conditioning layer.》
GANs:《Large scale GAN training for high fidelity natural image synthesis.》
《A style-based generator architecture for generative adversarial networks.》
对于Scale参数
和shift参数 ,并不是直接学习,而是在t和c的嵌入向量中去regress产生。 此方法中,Gflops的增加最小。 通过同一种函数,限制所有tokens。
addLN-Zero Block先前工作中,将ResNet块初始化为恒等函数是有益的。[《Accurate, large minibatch sgd: Training imagenet in 1 hour》对final batch的norm scale factor
进行零初始化,能够加速监督学习的大规模训练] Diffusion U-Net也有使用类似的初始化策略:在残差连接前,对每个块的最终卷积层进行零初始化。
于是,本文对adaLN DiT block进行了相同的策略:除了对
和 进行零初始化,以及在残差连接之前,还对dimension-wise scaling parameters 也是regress取得,同样零初始化。 MLP将初始化以输出所有
的零向量:这会使得DiT块初始化为恒等函数。 此方法中,Gflops的增加也很小,可忽略不计
Model size
N个DiT块,每个块在维度

Transformer decoder
在DiT块之后,需要将图像tokens变为输出噪声预测以及输出的协方差预测。(两个输出都与输入的形状一样)
使用linear decoder来实现:
最后一层layer
norm(adaLN若使用:先LN,然后shift和scale作运算),然后线性变换Linear为
Experiment
遵循ViT的操作,使用ImageNet作为基准数据集。
作者进行了一系列实验来研究不同 DiT 设计之间的区别,主要包括以下几个方面:
- DiT block 的设计:经过实验可以发现 AdaLN 的效果比其他的条件嵌入方式更好,并且初始化方式也很重要,AdaLN 将每个 DiT block 初始化为恒等映射,能取得更好的效果;不过对于比较复杂的条件,比如 text,可能用 cross-attention 更好;
- 缩放模型大小和 patch 大小:实验发现增大模型大小并减小 patch 大小可以提高性能;
- 提高 GFLOPs 是改善模型性能的关键;
- 更大的 DiT 模型的计算效率更高;
代码实现
主要需要关注的是模型的 DiT block 和 decoder。
1 | # 根据shift和scale进行相对归一化操作 |
条件c,经过adaLN_modulation,产生多个可学习的调节参数,然后对x进行偏移和缩放(
再对第二步的MLP也是一样的参数操作。
可以发现这些参数都是由同一个MLP计算(adaLN_modulation)
Decoder 则是由 AdaLN + Linear 组成:
1 | class FinalLayer(nn.Module): |
先经过LN,然后modulate运算,最后linear变换。
这些 adaLN_modulation 层在创建时被零初始化:
1 | # Zero-out adaLN modulation layers in DiT blocks: |