
论文阅读-LDM
code:
[!NOTE]
CompVis/latent diffusion: https://github.com/CompVis/latent-diffusion
CompVis/stable diffusion: https://github.com/CompVis/stable-diffusion
Stability-AI/stable-diffusion: https://github.com/Stability-AI/stablediffusion
stable-diffusion-webui: https://github.com/AUTOMATIC1111/stable-diffusion-webui
video:
[!NOTE]
slides:
[!NOTE]
相关work

Introduction
相关问题和提出的背景
References
Background
生成式模型:
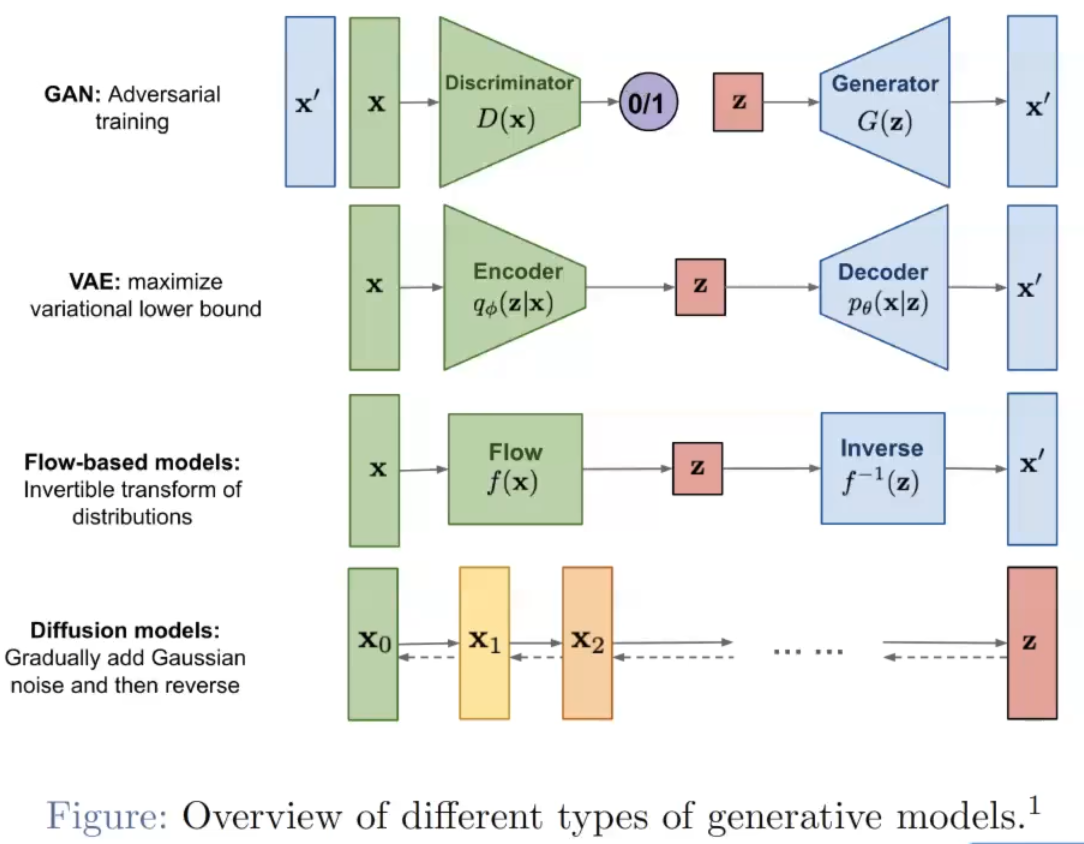
- GAN:交替训练两个模型discriminator,generator
- VAE:encoder学x的分布,然后从分布中sample一些作为decoder的输入,然后revocer出x。 又不离(0,1)分布太远,防止分布太夸张
- Flow-based:挑战在于inverse,network不好扭转回来。
- Diffusion-models:前向加噪,后向去噪
利弊对比
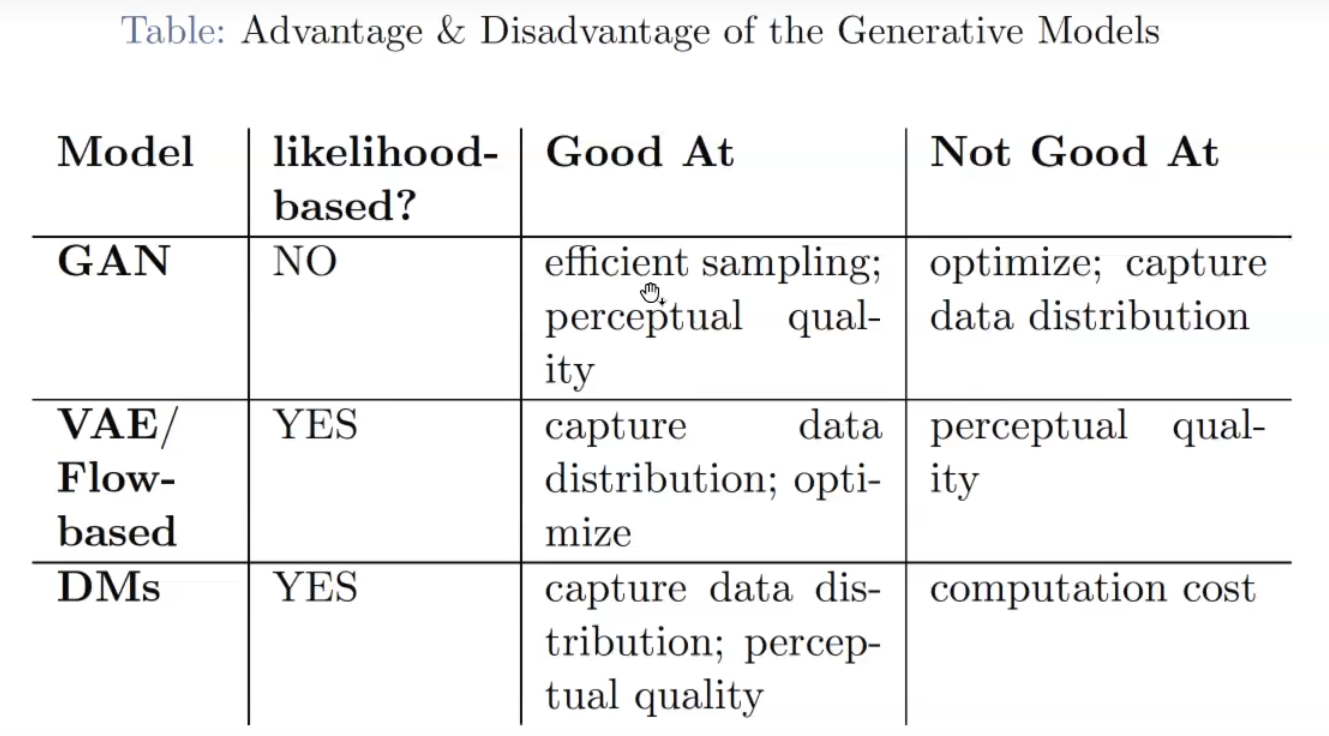
GAN: 缺点是难以优化,优势数据点会盖过其他点,捕捉不精准; 优点是跑得快,视觉效果还行
难以捕捉的话,就会造成一些不可能出现的场景,难以生成。
VAE/Flow:效果一般
DMs:缺点在于计算量,训练时间很长
术语解释
optimize: stable,是否稳定
capture full data distribution: 有能力生成没见过的图像
perceptual quality: 视觉效果,细节
History of Text-to-Image
2015: 图生文字
2016: 文字生图,但还比较模糊
难关攻克:从自然语言描述中生图?
2021:DALL-E(OpenAI) 不开源,而且是AR的思路,像素接龙
2021:GLide 开源
2022:DALL-E-2
Latent Diffusion Model: 可能效果不是最好的,但是开源。(不一定要是text条件)
2022的tools: SD,MidJourney,DALL·E-2(但有论文,可复现)

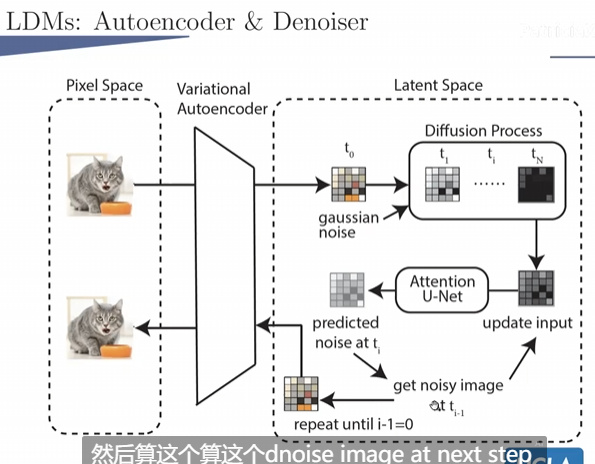
Latent Diffusion
模型本身
- Diffusion Model for Images
输入:random noise
一步步输出:前一步去噪的图片
最终输出:清晰的图
术语:
Diffusion Process:加noise
Backward Diffusion Process:逆向,去噪
why T steps?
拆解难题成小问题;
更容易条件的指导添加。
原理

主要是学习去噪过程,实现是原图 - 预测的噪音。
UNet会去预测噪音。
然后擅长学条件,就是加一个y,autoencoder。
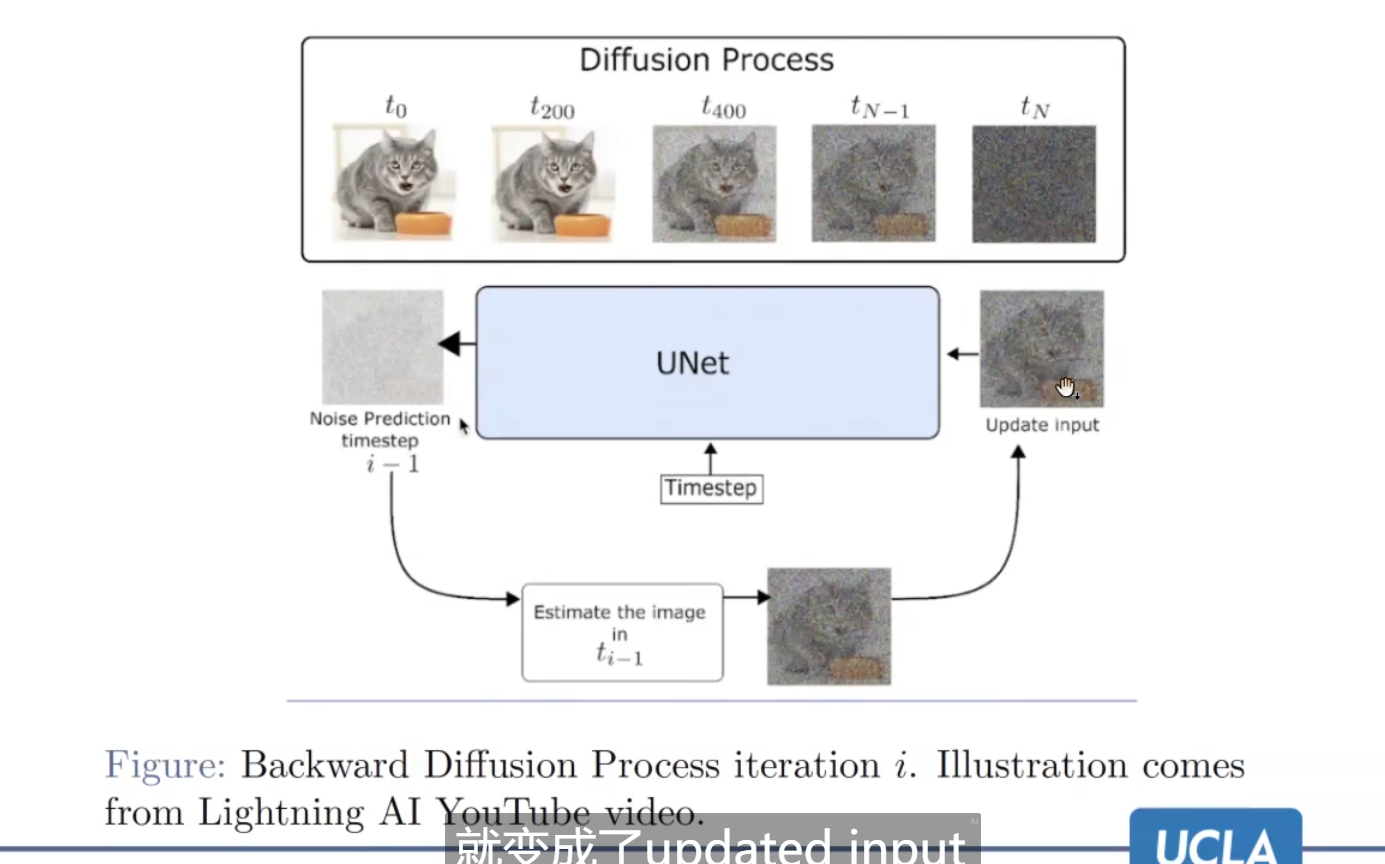
缺点:
训练昂贵:UNet架构的参数很多
推理也很慢:重新跑Unet的过程,步骤非常多。
认为的原因:模型去学习了很多无关紧要的,不影响视觉效果的细节。
Mode-Covering-Behavior
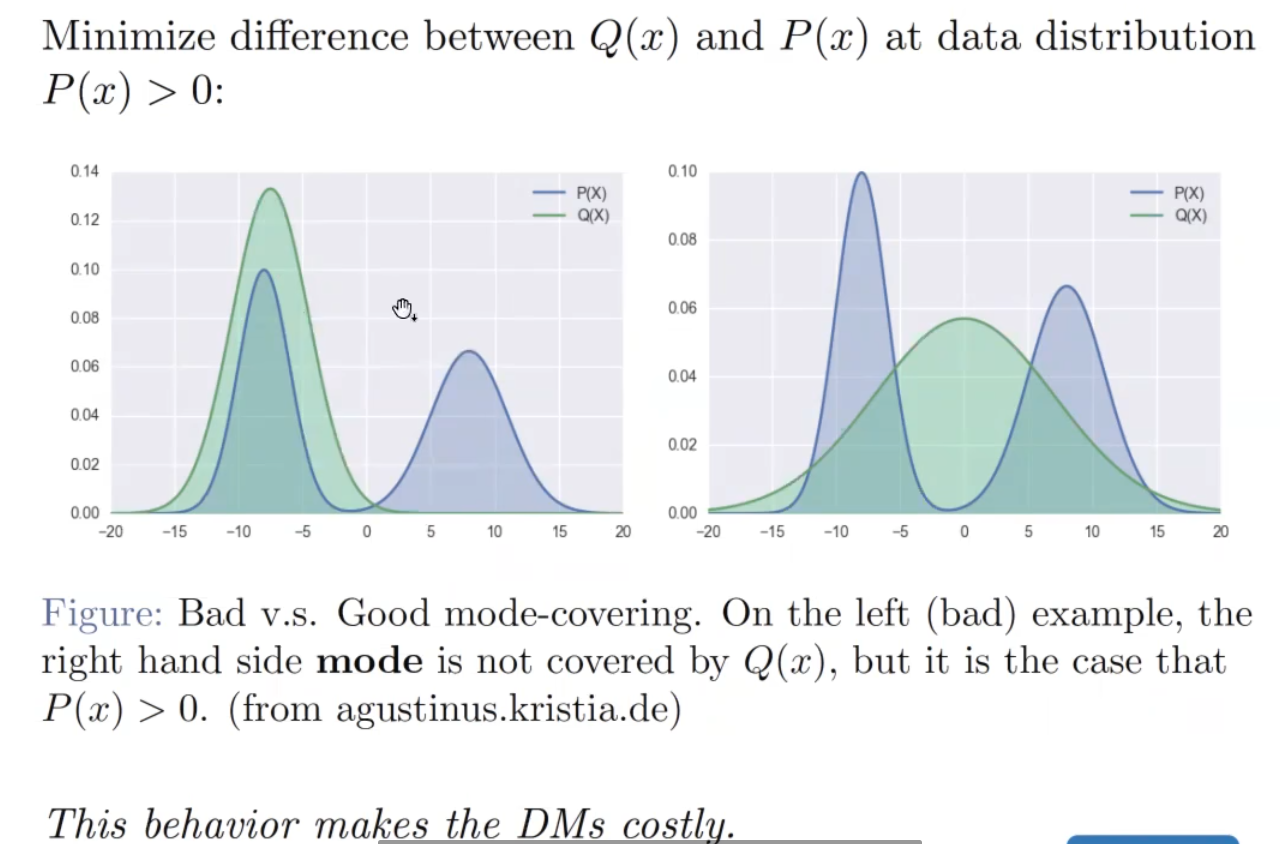
想要把两个峰都给覆盖掉,有一些无关紧要的细节,UNet也想去cover掉,浪费时间。
- Motivation
先前研究:
weighted importance of steps:给步骤赋权,有一些重要的才进行。(仍然expensive,因为太多了)
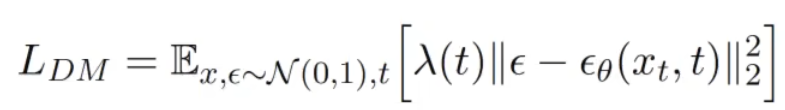
pixel space compress and upsampling&sharpening: 在像素空间,先把图片压缩,然后再过采样重构。 如GLIDE
有研究表明,pixel空间就是有很多无关的点,没必要学习。
Latent space:
最大创新点
把diffusion的process,彻底搬到了latent space。
对于条件的接收更宽泛
好处
耗费更少
灵活,condition
- Architecture
LDMs:
有三个组件,Autoencoder,Denoiser,Conditioning Encoder,且可以分开训练。
Autoencoder: 将RGB 和 latent的互相转换,VAE实现, 使用了一些regularization term训练得合适一些。
Denoiser:学习如何把latent
representation复原回pixel,可视作a time-conditional attention UNet
Conditioning Encoder: 指导
对比DMs的条件引入机制:

DM是直接建模条件和图像,LDM主要是通过UNet的交叉注意力来引入条件。
LDM架构:
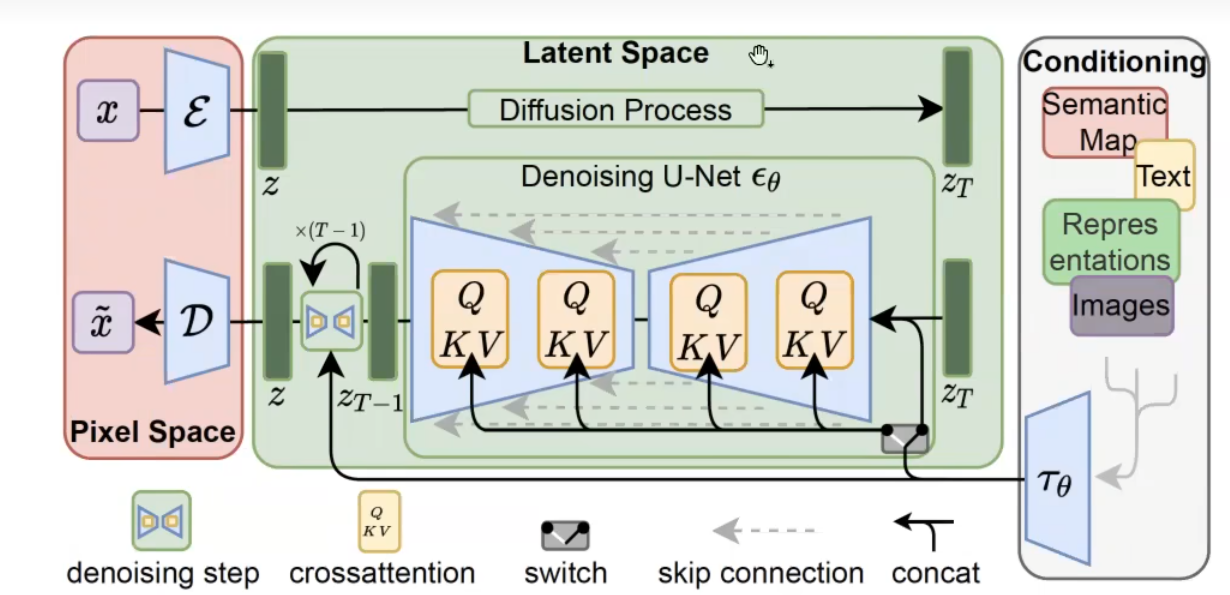
注意:编码和解码的VAE不是同一个。
加condition:
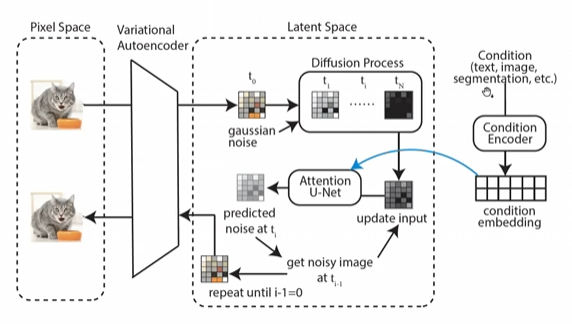
具体的生成过程:
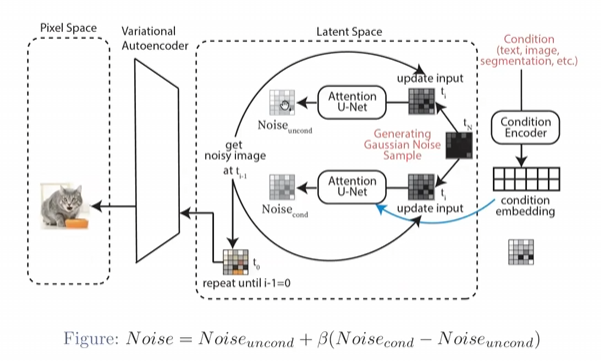
生成两个噪音,一个版本考虑condition,一个版本不考虑condition
最后同时生成一个预测得到的噪音。 这么做的好处就是让图像能往condition的部分偏移,同时又能保证自己的生图质量。
Denoiser:UNet架构
special kind of convolutional-based model. 一种特殊的卷积模型
卷积模型如图:
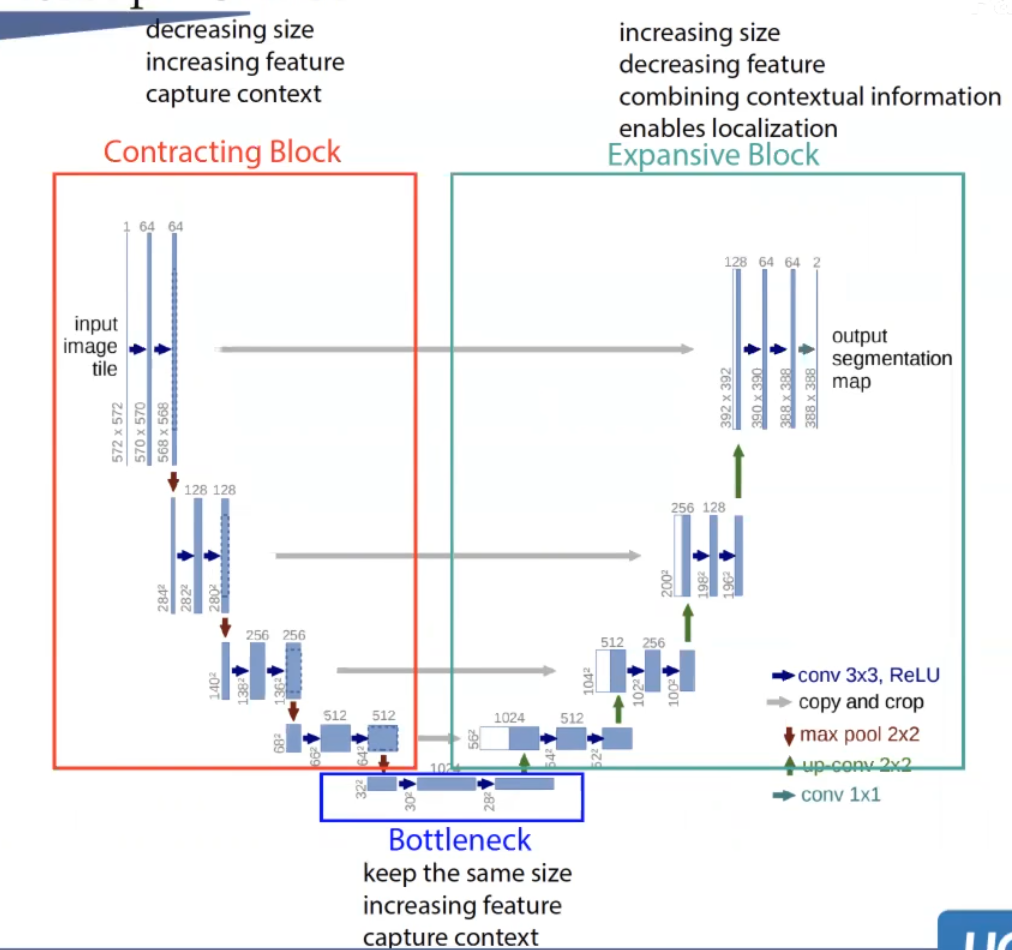
而UNet的结构图:

好处是:capture图片的局部信息准(local information)
分为三个部分: 最初是为了image segamention提出
Contracting Block:降低图片size,但是增加feature dimmension,学习语义信息
BottleNeck:保持size,增加feature dimmension,学习信息
Expansive Block:还原图片size,减少特征维度,融合信息,局部特征体现明显
但是LDM使用的UNet是改良版:
原版箭头是conv relu,换成了ResNet+Spatial Transformer
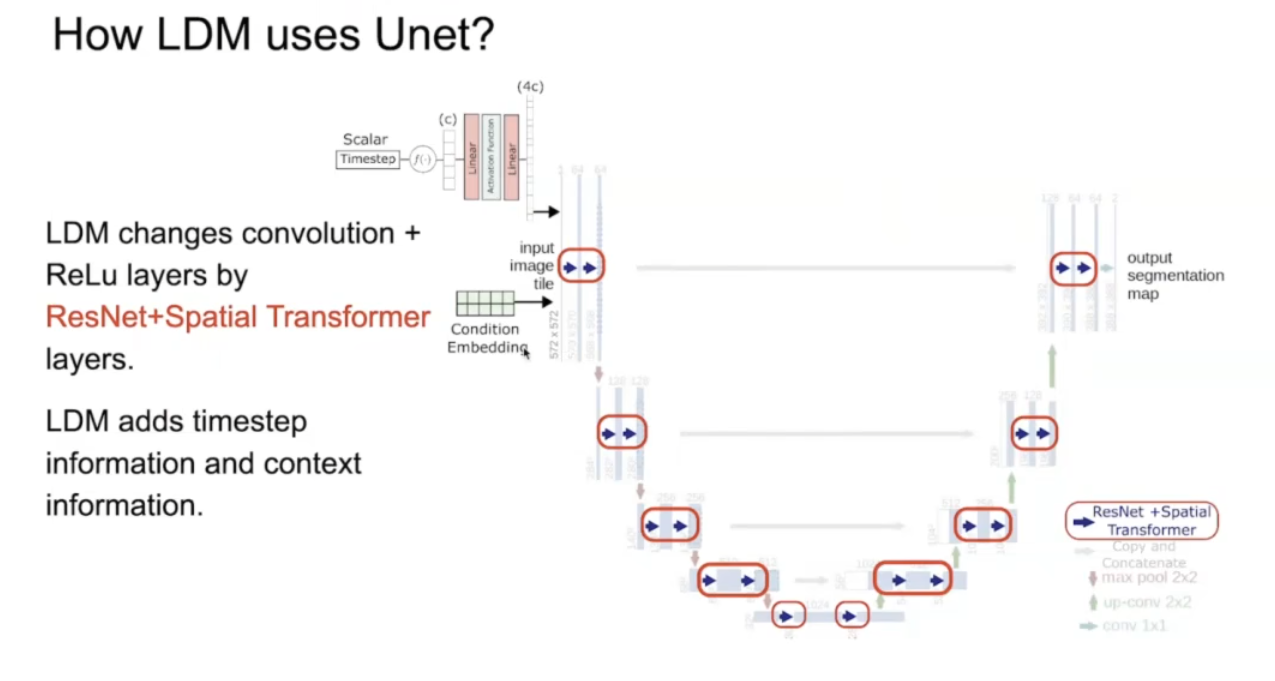
ResNet会去考虑time step的信息:
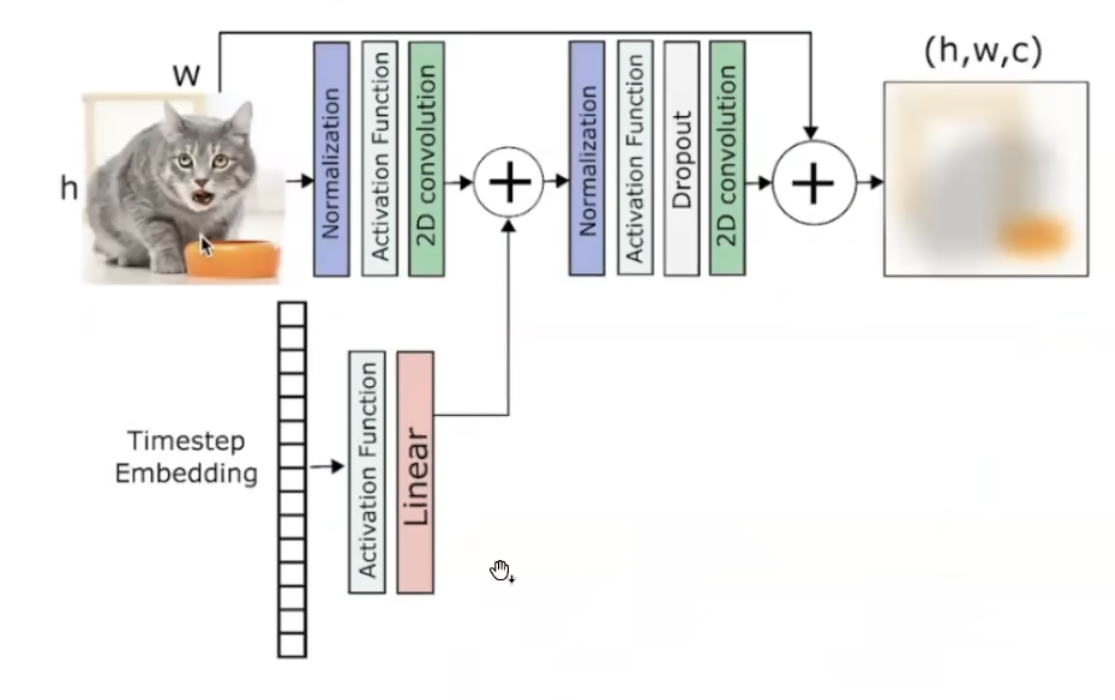
Spacial Transformer:
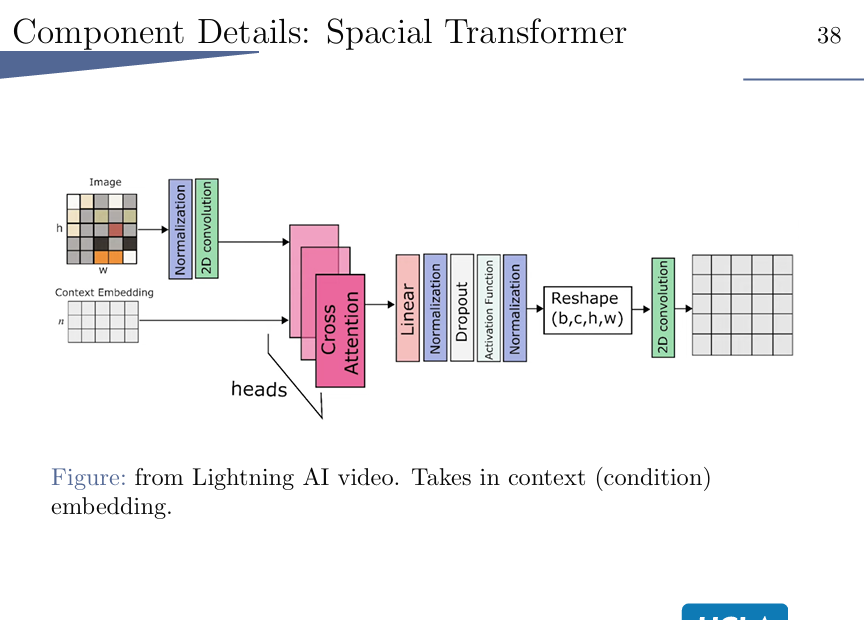
考虑进context embedding信息。
关于这个attention和cross attention:
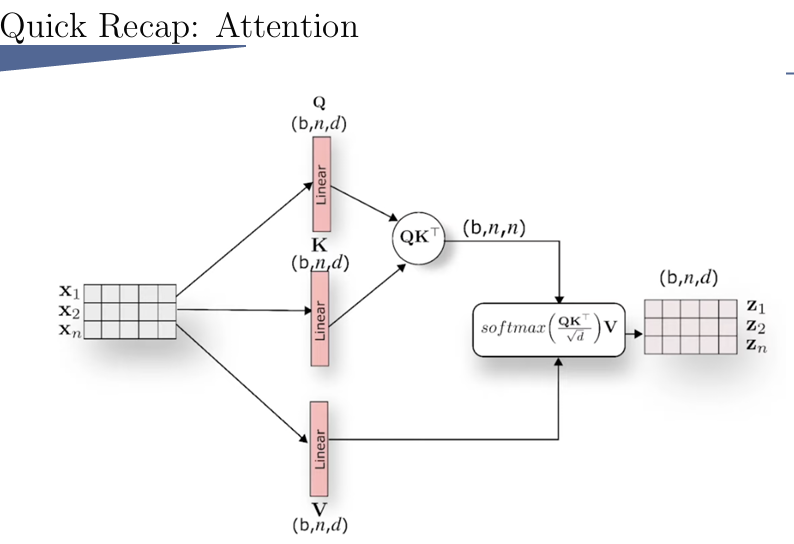
query到和key越相似的,则这个value就被认为越重要。
cross attention:
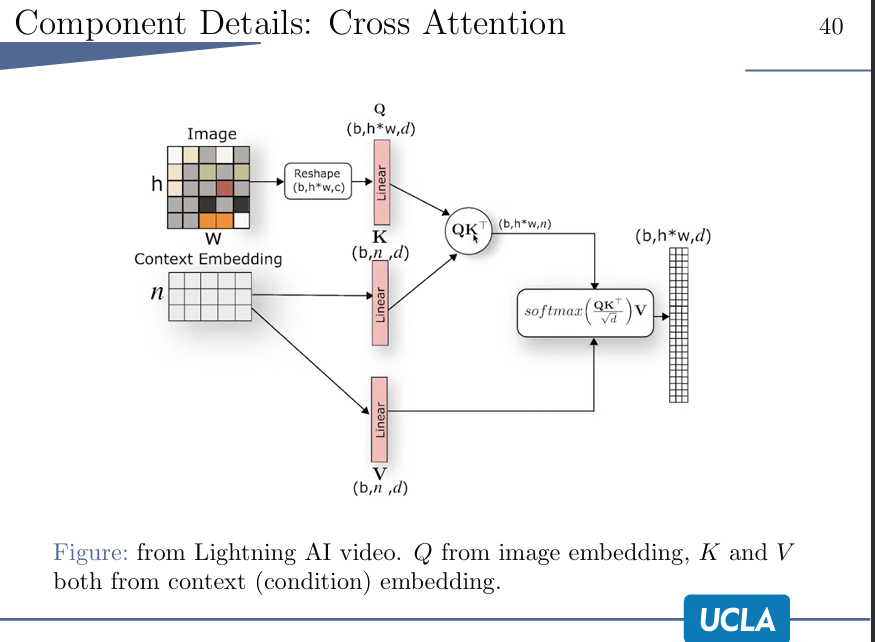
引入context来指导image上的信息的重要性。
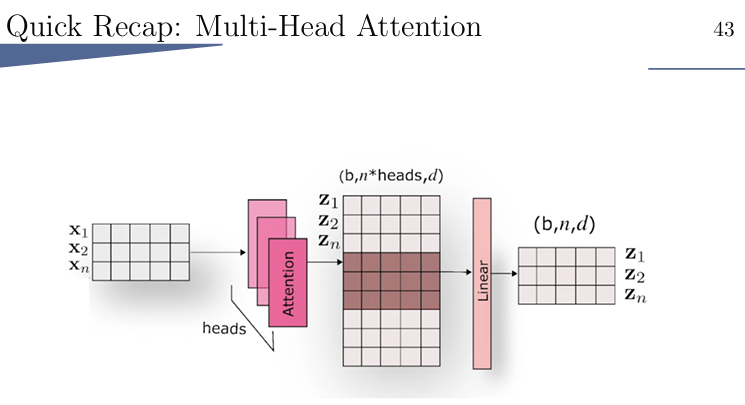
cross attention,严格来说是一种multi-head attention

比如说it这个词,可以关联到animal,也能关联tired,若只进行一次attention,那就会只关联到一个,所以要多头attention。
在图片中的这个多头attention的含义:

刺猬过街。 那么图片中要有刺猬,也要有街,所以要有多次attention。
AutoEncoder
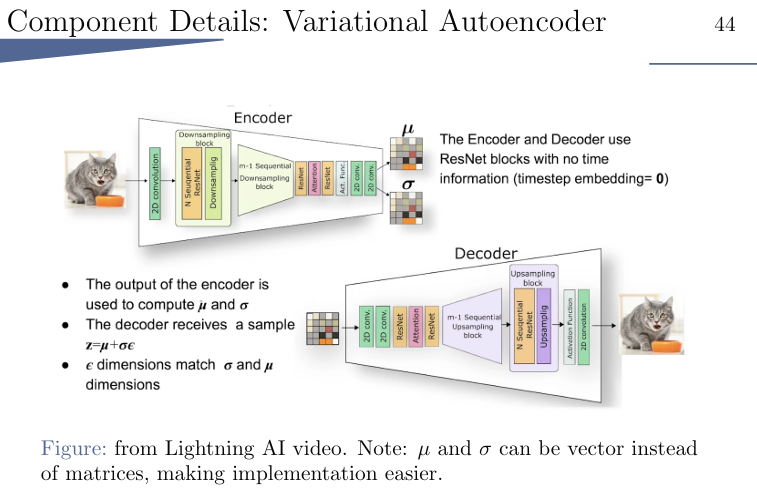
用了很多ResNet Block,但不带time information。
encoder学习x的分布,即算一个μ和σ
decoder接收一个从分布sample的东西latent representation: z
VAE中的Attention:
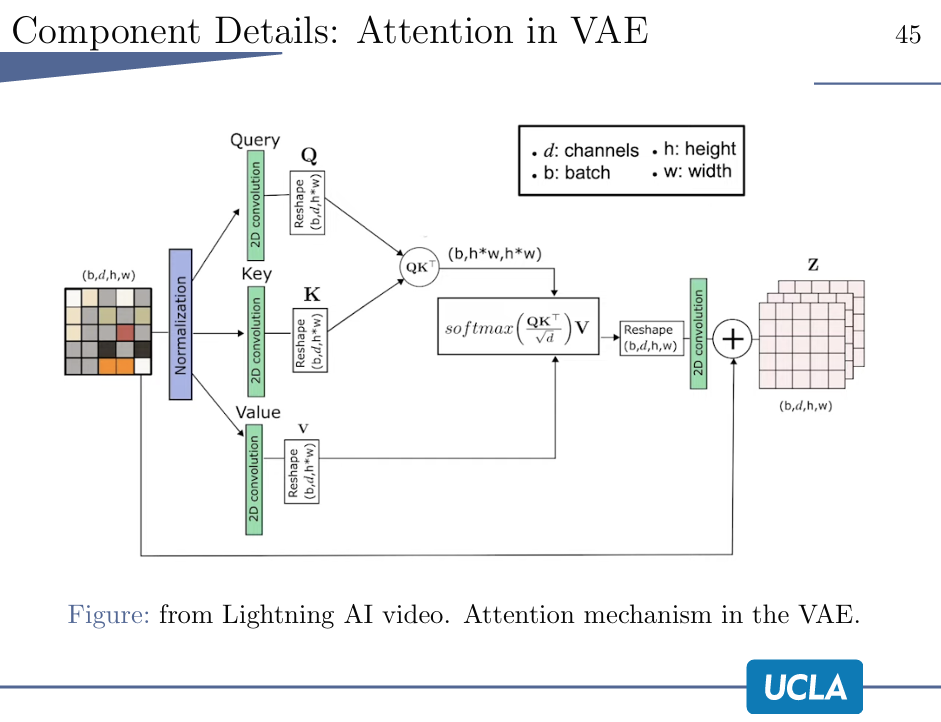
此处就是一个self-attention,先经过normalization,然后QKV,最后reshape,卷积再加到一起。
Condition Encoder
可以是任何东西,但此处选择的是CLIP
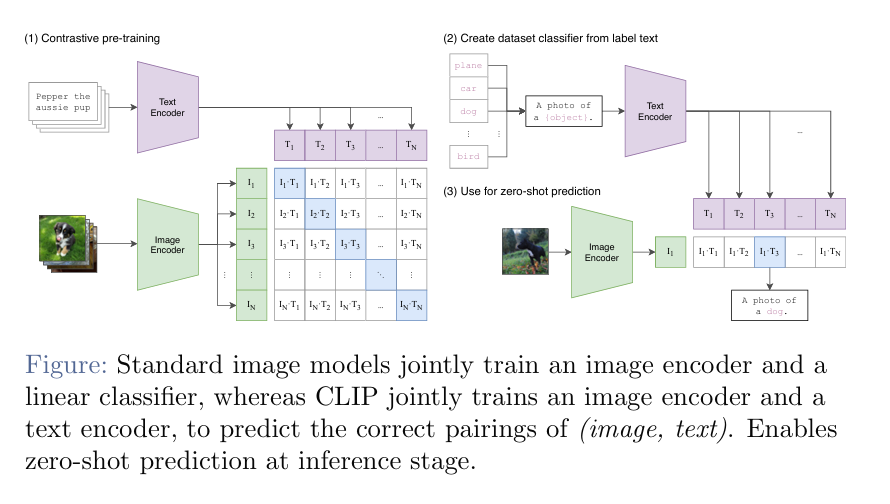
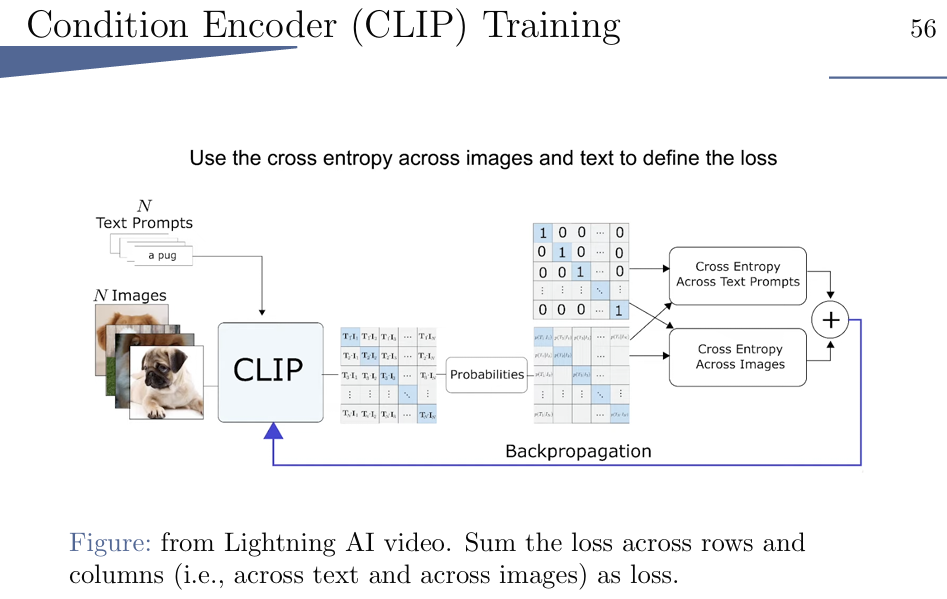
沟通的是text和image的桥梁,两个都经过一个encoder,然后放到一起,看能不能match,乘到一起,交叉熵。此处CLIP的encoder是正常transformer的。 不一定zero-shot(零样本,马+条纹->斑马),也可以fine-tuned。


CLIP也有局限性,不是所有数据集上都表现得好;无法生成或者说标注,只是选择结果

- Training
训练过程,AutoEncoder,Denoiser,condition encoder
一般是把AutoEncoder先训练好,然后Denoiser和condition encoder一起训练。
训练AutoEncoder:
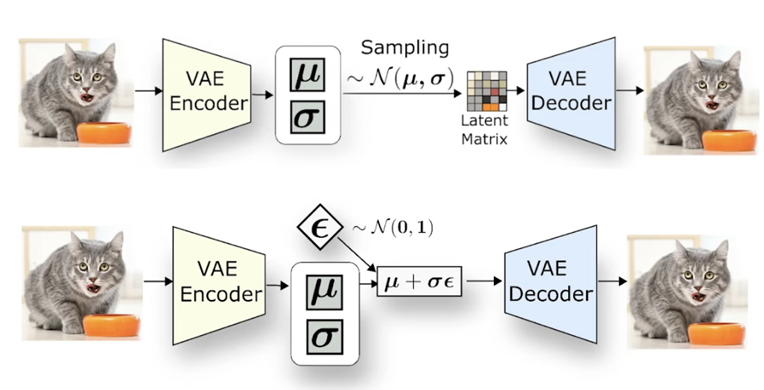
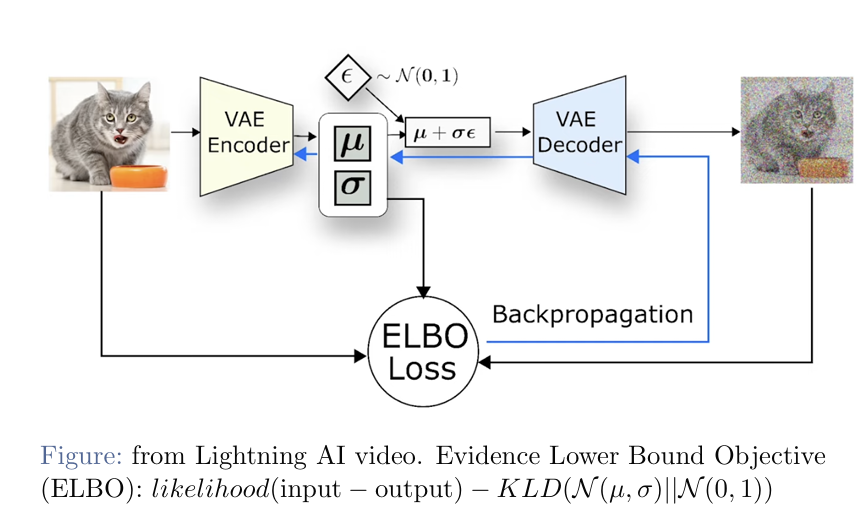
encoder学出一个μ和σ,然后denoiser学出一个ε,组合到一起,输入到decoder。
然后做反向传播时,计算的是ELBO loss,likelihood - KL散度
(公式推出来是这样)
likelihood就是希望encoder和decoder出来的结果不会太离谱; KL散度就是看μ和σ与(0,1)分布差得远不远
训练UNet:
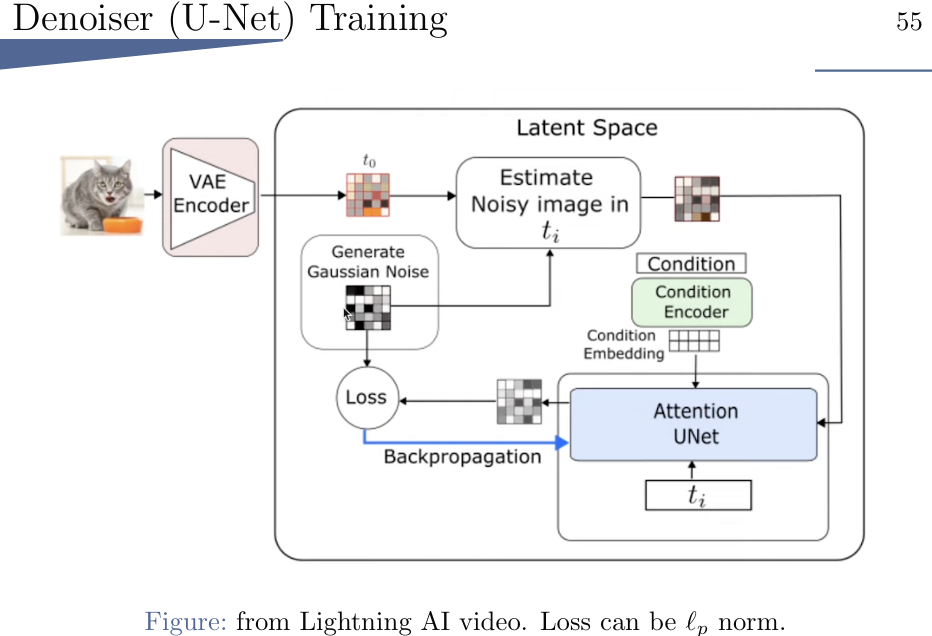
训练时,对比gaussain noise和predict noise算loss。
训练conditional encoder:
- Applications
可以做一些分割,超分,修复等
还能够进行 few-shot learning
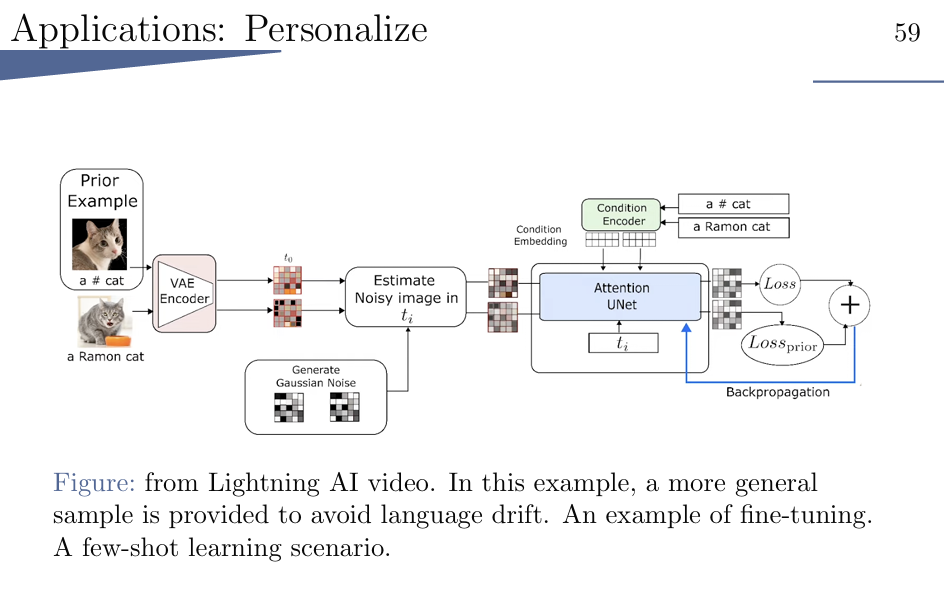
担心只学会ramon,而学不会cat,就多加一个prior example让他明白是cat。
Conclusion
模型细节,相关工作对比,社会影响
- more on latent/stable diffusion
- similar works
- social impact
Q:LDM和SD是一样的吗?
虽然model和code基本一样,stabilityAI,LAION
但是SD用的数据集更好,所以效果会和别的就不一样了。
相关工作:
DAAL·E,two stage, GPT-LIKE

DALL·E-2:分开训练

GLIDE:pixel space


对比: LDM vs GLIDE
数据集不一样!

注入条件的方式:
1.用CLS去标记图片 2.每个UNet都算一遍text token的注意力。 但是GLIDE试了,效果都不好。
于是GLIDE就用了CLIP SCORE去帮助比较注入的条件是否合适。

还有什么更好的方法? CFG
生成图片的时候,一次有text,一次没有text
然后计算两个结果的差值,然后把image往text的方向挪一挪。 Classifer-Free Guidance LDM就采用了这个。

classifer 是引入一个额外的分类模型去指导。

与DALL·E-2的对比:

数据集不同,架构不同,LDM的condition更加丰富,注入条件的方式不同。

有两个版本:
AR
Diffusion


QA
Q:ldm是在VAE得到的latent space上进行训练的话,为什么其采样精度要优于VAE呢
A:因为ldm的VAE不预测正态分布,仅压缩图像,通过扩散过程映射到正态分布。VAE单独作为生成模型,直接把图像映射到正态分布,效果肯定没有ldm好,变分推断做了一次近似,训练又是一次近似。简而言之,同样是把原始数据分布映射为正态分布,扩散过程的能力比单独VAE的能力强